The 2025 Localization Playbook: TEP vs MTPE—When to Use Which
Choose the right workflow in 2025. This playbook shows when to use TEP (human translation + edit + proof) and when MTPE makes sense—plus a decision matrix, quality bars, a pilot plan, and risk controls.

The 2025 Localization Playbook: TEP vs MTPE—When to Use Which
Budgets are tighter, deadlines are shorter, and content types keep multiplying—product UI, help centers, app stores, ads, videos, even prompts. The fastest way to ship confidently in 2025 is choosing the right workflow for each content stream:
TEP (human Translation + Edit + Proof)
MTPE (Machine Translation + human Post-Editing)
Below is a practical, no-nonsense guide you can run with your team today.
TL;DR (the one-minute version)
Pick TEP when content is brand-critical, legal/regulated, marketing-heavy, or long-lived (manuals, onboarding, clinical, compliance).
Pick MTPE—Full for high-volume docs with moderate brand risk, where quality must be “publishable,” but speed and cost matter.
Pick MTPE—Light for utility content: knowledge base, release notes, user-generated content, internal docs, or when you only need “good enough.”
Hybrid wins in most orgs: MTPE for bulk + TEP for hero/critical pages and campaigns.
What exactly are TEP and MTPE?
TEP
A classic three-pass human workflow. A translator drafts, a second linguist edits for accuracy/style, and a final proof pass checks typography, layout, and consistency. It’s slower and costlier—but consistently premium.MTPE
A machine engine drafts the translation. A human linguist then post-edits (light or full), correcting meaning, grammar, and terminology per your style guide & glossary. It’s faster and cheaper—if the content and language pair are suitable.
Quality bars: Utility vs Publishable vs Regulated
Utility: understandable for the task; minor style issues are acceptable. Example: internal tickets, KB articles, time-sensitive notifications.
Publishable: accurate, on-brand, reads natively; fit for external audiences. Example: product UI, docs, app store listings.
Regulated: requires strict accuracy, traceability, and often two human linguists or certifications. Example: legal, medical, clinical trials, T&Cs.
Mapping: MTPE-Light → Utility | MTPE-Full → Publishable | TEP → Publishable/Regulated
Decision matrix
FactorIf this is true…RecommendedBrand/Legal riskHigh (brand voice, legal exposure, regulated)TEPDomain complexityHigh (medical, legal, finance, marketing nuance)TEP or MTPE-Full with strict LQAVolume & speedVery high, ongoingMTPE-Full (bulk) + TEP for criticalContent lifetimeLong-lived (manuals, onboarding)TEP or MTPE-Full with extra reviewContent typeKB, support, internal opsMTPE-LightSource qualityNoisy/messy, poor English, many placeholdersTEP (or fix source, then MTPE-Full)Language pair riskLow-resource pair or very morphologically complexPilot first; expect more human effortFormat complexityRich layouts, RTL/CJK, SEO pages, ad copyTEP or MTPE-Full + in-context LQAPrivacy/PIISensitive personal dataTEP with vetted team; in-tenant optional
MT suitability checklist
Clear, well-written source (simple sentences, consistent terminology).
Known domain with good training coverage (tech/product docs, support).
Language pairs supported strongly by modern MT (e.g., EN↔ES/FR/DE/IT/PT, many Asian/EU majors).
Glossary & style guide in place.
Risk tolerance: utility/publishable—not legal/regulatory.
You’ll run a pilot (sample + LQA) before scaling.
If you’re unsure, run two small pilots side-by-side: TEP vs MTPE-Full on the same sample and compare cost/quality/speed.
Light vs Full MTPE (and the Hybrid everyone forgets)
MTPE-Light
Fix meaning errors and obvious grammar.
No heavy re-styling.
Target: Utility content; max throughput, lowest cost.
MTPE-Full
Correct all meaning and grammar, align with brand voice, enforce glossary.
Target: Publishable content; solid middle ground.
Hybrid
Bulk to MTPE-Full (docs, KB, UI strings).
Critical pages/campaigns to TEP (hero pages, pricing, ads, legal).
Add in-context LQA for UI/marketing just before ship.
The pilot-then-scale method (use this template)
Pick a representative sample (1–2k words or ~150 UI strings) per language.
Define acceptance criteria (LQA threshold, allowed error classes, style goals).
Run TEP and MTPE-Full on the same sample; time the effort.
Score with LQA (major/minor errors) and reader tests if needed.
Decide per content stream: bulk → MTPE-Full; critical → TEP.
Lock glossary & style guide, then scale with sampling (2–5% LQA).
Review quarterly—language pairs evolve; you may move streams between tracks.
We can run this for you and send a side-by-side report with cost/time/quality deltas.
Risk controls & governance that actually work
Glossary + termbase enforced in CAT/TMS.
Style guide with voice & examples per market.
Sampling LQA on every batch (2–5%).
Fallback rule: if a batch fails, escalate to TEP or add a second pass.
In-context review for UI, marketing, and subtitles before ship.
Security: NDA, role-based access, encrypted transfer; in-tenant option if you need full isolation.
Budget & timeline reality check (example math)
Say you have 50,000 words of product docs in 4 languages.
TEP: 8–10 working days/language, premium quality.
MTPE-Full: ~40–60% faster with 20–35% cost reduction if the checklist is green.
Hybrid: Put 80% of docs to MTPE-Full; 20% (UX copy, release notes, landing pages) to TEP → best balance of brand safety and speed.
Numbers vary by domain and language pair—hence the pilot.
Implementation checklists (by content type)
Product UI
Freeze strings → extract keys → run MTPE-Full → in-context LQA → screenshots for sign-off.
Docs & KB
MT suitability check → MTPE-Full → automated link/variable checks → publish → monthly LQA sampling.
Marketing
Headlines/ads/hero → TEP.
Long-tail blogs/FAQ → MTPE-Full + marketing editor pass.
Legal/Regulatory
Always TEP (often with two linguists + legal review).
What Saytica brings
Suitability audit per language pair & domain.
Hybrid programs: MTPE for bulk + TEP for brand/legal.
In-context LQA for UI/marketing.
Media & DTP teams to finish assets (subs, dubbing, print-ready PDFs).
Security: NDA, encrypted transfer, in-tenant operations on request.
Tags
More Articles
Explore more from our blog
The rare-language problem that the localization industry pretends doesn't exist
A tier-1 global agency came to us last year after exhausting their network on four languages out of eighteen. Sylheti, Rohingya, Khasi, Mizo. The story of how that project went says a lot about a gap in our industry that most agencies don't want to talk about openly.
Why most SaaS localization workflows can't keep up with continuous deployment
A SaaS client came to us with a problem that took me a while to fully understand. They were shipping product faster than their localization workflow could move. Three vendors, 25 languages, 5-day turnaround, and roughly 1 in 6 sprints missing translations at release. Here is what we found when we rebuilt their pipeline.

How we localized an AI product into 40 languages in 6 weeks
A conversational AI company came to us last quarter with a hard deadline: 40 languages in 8 weeks. Their incumbent agency quoted 14. We delivered in 6, including 12 languages the tier-1 LSP had declined to touch. Here's what we learned about localizing AI products that translation work doesn't teach you.
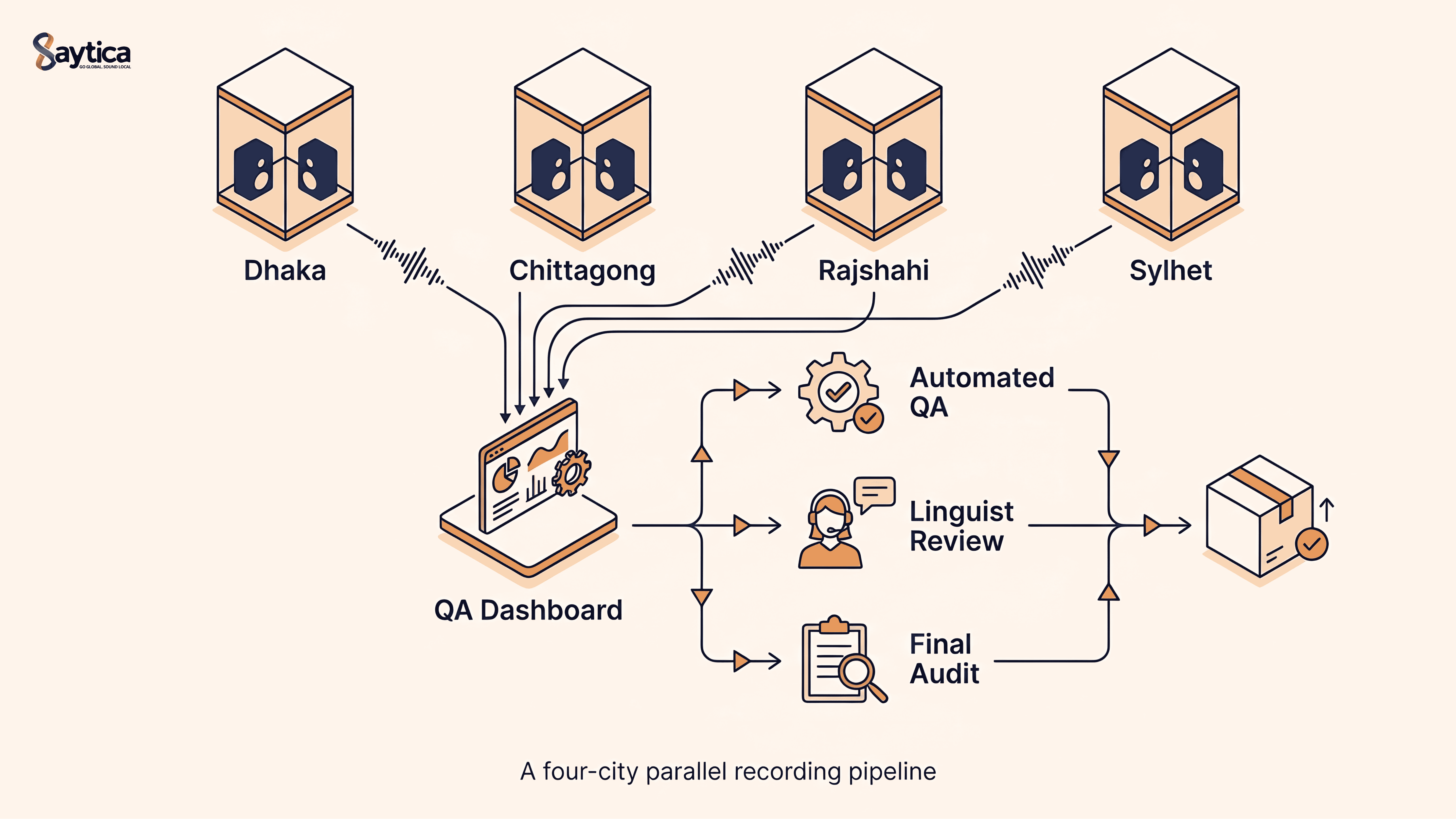
How We Collected 500 Hours of Bangla Duplex Conversational Audio in 6 Weeks — 32% Cheaper, 25% Faster
A global AI lab needed 500 hours of dual-channel Bangla conversational speech for ASR fine-tuning in 8 weeks. We delivered in 6 — at 32% below benchmark cost. Here's exactly how, end to end: speaker recruitment, parallel multi-city recording, three-layer QA, and the operational decisions behind the gains.

Subtitles That Don’t Feel “Machine”: Read-Speed, SDH & Platform Specs
Why some captions feel robotic—and how to fix them fast. A practical guide to read-speed, SDH vs. standard subtitles, on-screen text, and a simple QC checklist you can run before publish.
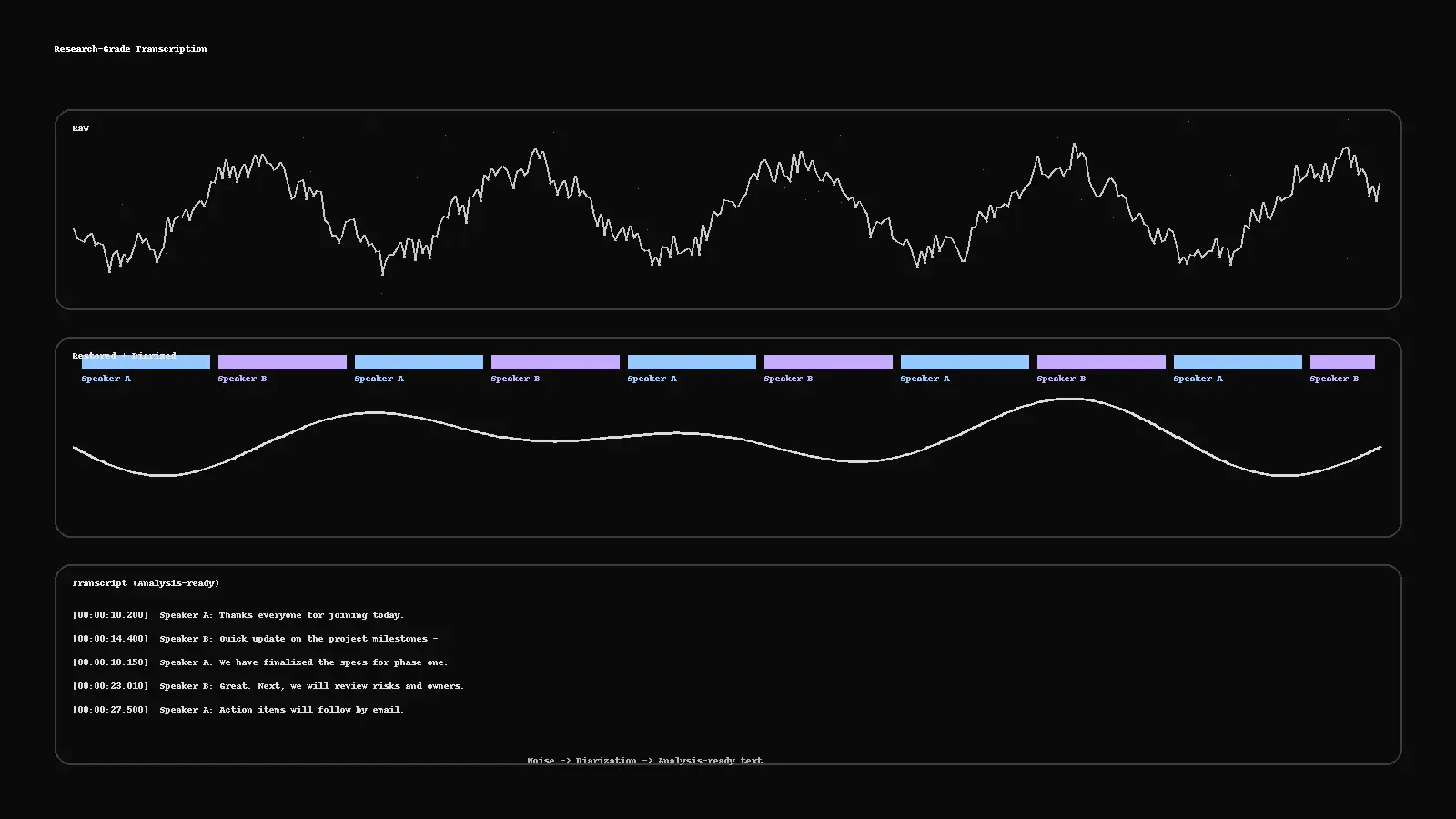
Research-Grade Transcription: From Noisy Audio to Analysis-Ready Text
Turn messy recordings into clean, analysis-ready text. This guide shows a practical pipeline—restoration, diarization, human QC, PII redaction, and deliverables (RTTM, ELAN, TextGrid, SRT)—plus a two-minute checklist to run before publishing.